Deep learning is a subset of machine learning that leverages deep neural networks to identify complex patterns. This knowledge-base article outlines core concepts, architectures, training principles, applications and key limitations in a business-focused, factual manner.
Why is deep learning relevant for organisations and development teams?
Deep learning makes it possible to analyse unstructured data such as images, text and audio at scale and turn it into actionable output. This delivers practical benefits for automation, decision-making and product innovation.
Key points
Definition and basic concepts, including neural layers, activation functions and backpropagation.
Common architectures such as convolutional networks, recurrent networks and transformer-based models.
Training practices, dataset requirements and evaluation criteria.
Applications and well-known limitations, including bias, explainability and computational cost.
Actionable insight
When implementing, first assess data quality and business value.
Consider pre-trained models and fine-tuning as an effective route to product integration.
Include governance and privacy measures early in the project.
What is deep learning and how does it relate to machine learning
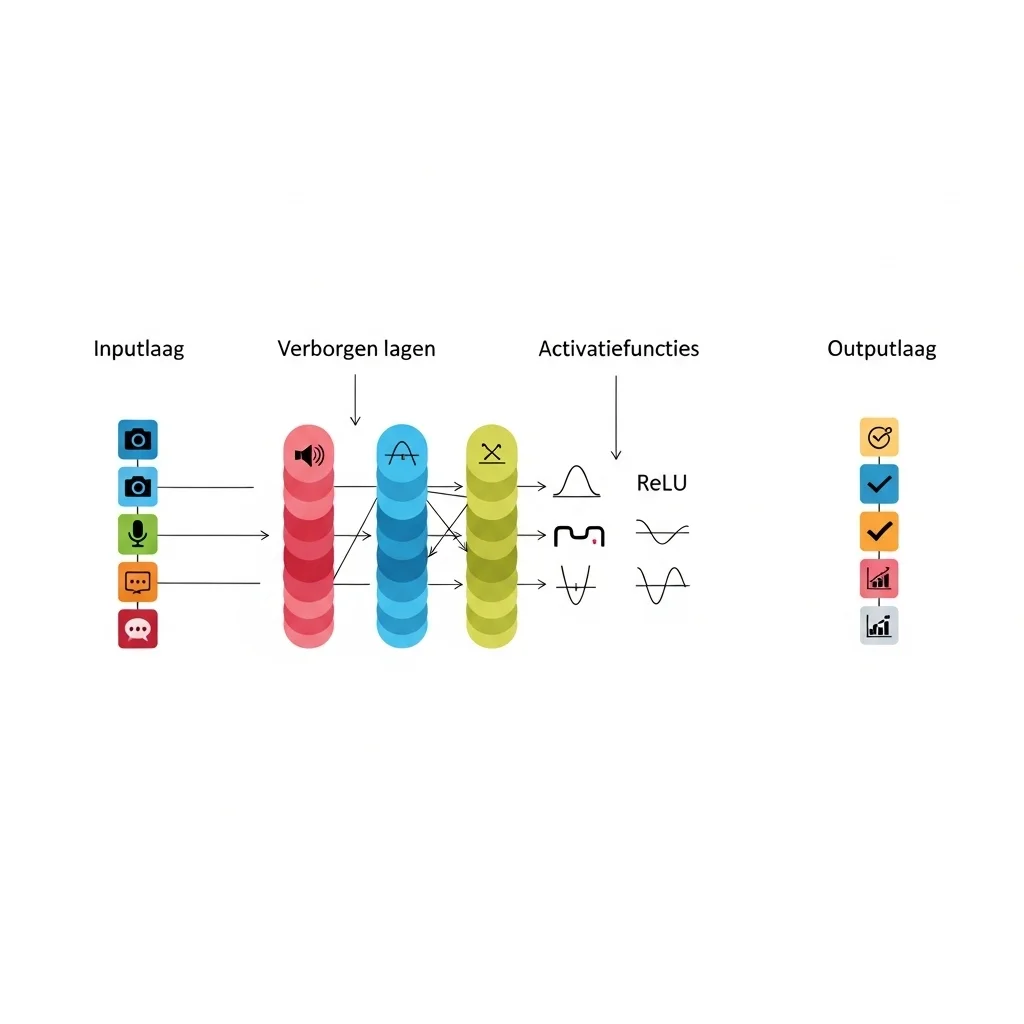
Deep learning is a branch of machine learning that employs models with many processing layers, the so-called deep neural networks. These networks learn data representations at different levels of abstraction, enabling them to capture complex patterns that classical methods struggle to uncover. In technical terms, a deep network consists of successive linear transformations followed by non-linear activations, and the parameters of those transformations are learned through optimisation, usually gradient descent and backpropagation.
Key differences from traditional machine learning include the degree of feature engineering and scalability. Whereas traditional methods require extensive manual preprocessing, deep networks can handle raw or lightly preprocessed data effectively, provided that enough examples are available. This makes deep learning particularly suitable for tasks such as image recognition, speech transcription and natural language processing, applications that currently attract considerable attention in both research and industry.
Core components of a deep neural network
A typical deep model contains input layers, hidden layers and an output layer, each composed of neurons that perform weighted summation and activation. Activation functions such as ReLU, sigmoid and softmax define the network's non-linearity. To promote training stability and better convergence, techniques such as batch normalisation, dropout and weight regularisation are applied.
The learning process revolves around a loss function that quantifies model behaviour and an optimiser that determines parameter updates. Popular optimisers include stochastic gradient descent with momentum, Adam and RMSprop. For successful training it is crucial to tune hyperparameters carefully, including learning rate, batch size and architectural templates such as layer depth and width. These choices largely determine the model's ability to generalise to new data.
Architectures and their typical use cases
Convolutional neural networks, often abbreviated as CNNs, are ideal for image and video signals because convolutions capture local patterns and translation invariance. Recurrent networks and variants such as LSTM and GRU were traditionally used for sequential data, for example time series and text. Over the last few years, transformer-based models have come to dominate natural language processing and are increasingly applied to multimodal tasks thanks to their ability to model long-range relationships in data.
Beyond these classic types, specific architectures exist for tasks such as object detection, semantic segmentation and generative modelling. Generative adversarial networks and diffusion models are examples of structures used to create new, realistic samples and they contribute significantly to applications in the media and creative industries.
Training data, compute and evaluation criteria
The performance of deep models depends heavily on dataset size and diversity. For many applications, pre-trained models and transfer learning offer a practical route because these models have already learned general representations on large datasets and can be adapted to specific tasks with relatively little additional data. Important steps in the data preparation process are checking annotation quality, verifying representativeness and assessing bias risks.
Computational cost remains a key consideration. Training large models can demand substantial GPU or TPU resources, and operational costs after deployment influence architectural decisions. In production environments, latency, throughput and scalability are relevant metrics. Evaluation typically relies on separate test sets, cross-validation and task-appropriate metrics such as accuracy, F1-score, ROC-AUC for classification and mean average precision for detection.
Safety, privacy and ethical aspects
When deploying deep learning in business contexts, governance, privacy and explainability are indispensable. Models can reproduce or amplify biases present in the training data, leading to unequal outcomes. Regulatory frameworks and privacy requirements such as the GDPR demand data minimisation, purpose limitation and adequate security. Technical mitigations include data anonymisation, fairness audits and the use of explainability methods such as SHAP and LIME to gain insight into model behaviour.
Organisations are advised not to view models in isolation from the decision processes they support. A governance structure that includes documentation, version control and post-deployment monitoring helps manage risks and fosters continuous improvement. Further guidelines on governance and practical implementation of AI projects are described in relevant articles and workshops on AI governance, see also the overview on the Spartner site, for example the page on getting a grip on AI governance.
Relevant technologies and integration in software projects
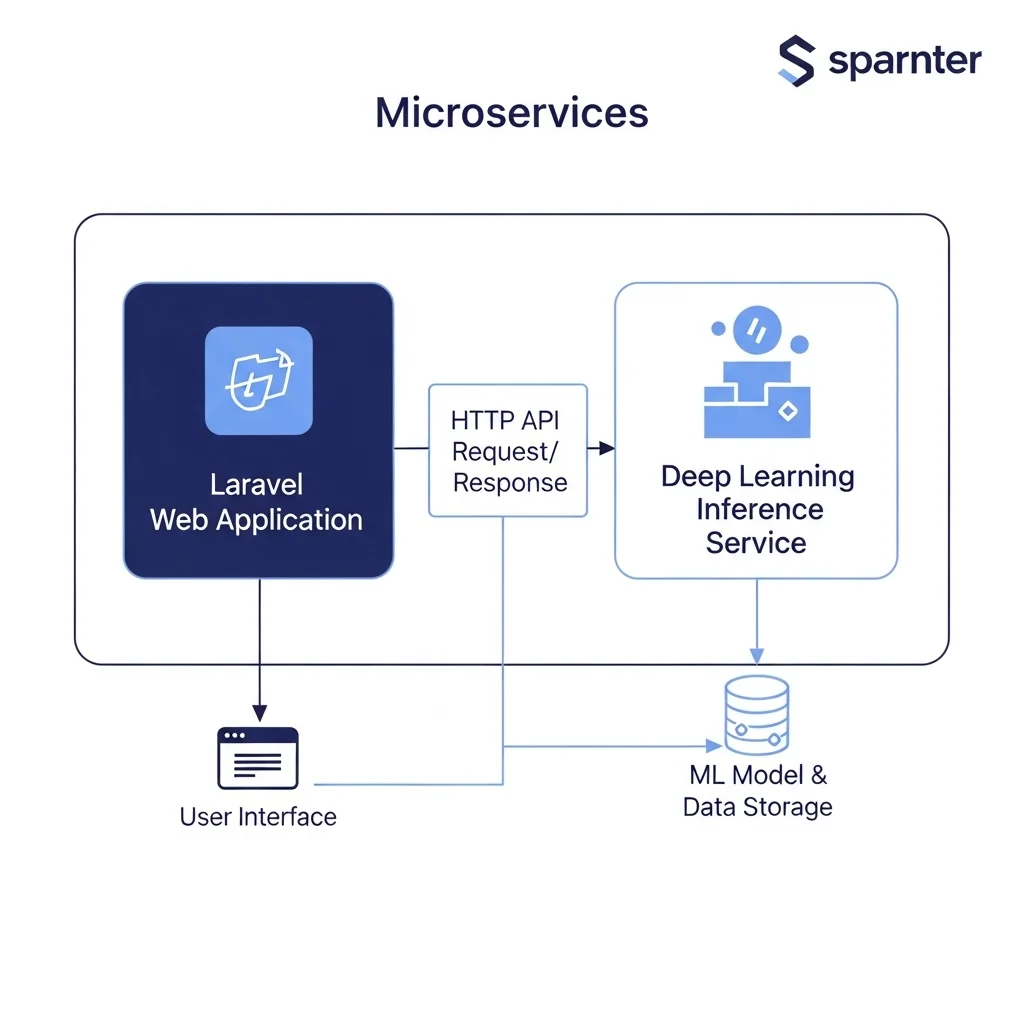
Integrating deep learning into existing applications requires technical choices around model deployment and API architecture. Using model-serving frameworks, containerisation and scalable inference platforms makes it possible to run models reliably in production. For many business applications it is efficient to separate inference from the main application and work with asynchronous queues or microservices for heavy processing tasks.
For teams working with Laravel and modern web stacks, integration is possible via HTTP APIs or dedicated microservices. Spartner documents examples of AI integration and productisation on the site, including solutions for chatbots and automated content workflows; see the page on custom AI chatbot and the introduction page getting started with AI. For content production and SEO-driven workflows, automatic integration of AI systems opens opportunities to accelerate repetitive tasks, as described on the page AI content creation.
Important considerations during integration are model versioning, monitoring for drift in the data distribution and rollback or fallback mechanisms when the model produces unexpected output. These operational aspects are crucial for sustainable deployment.
What is the main difference between machine learning and deep learning?
Machine learning covers a broad spectrum of methods that learn patterns from data. Deep learning is a subset that uses deep neural networks with multiple layers. These networks learn hierarchical representations, enabling them to tackle more complex tasks, often with less manual feature engineering.
What is the minimum amount of data required for successful deep learning?
There is no fixed lower bound, but in practice more data is generally better. For specialised tasks transfer learning can be a solution, where a pre-trained model is fine-tuned with a limited additional dataset. In our experience, for many commercial applications a few hundred to a few thousand representative examples already yield valuable results, provided those examples are of high quality. 🙂
Which frameworks are most commonly used for deep learning?
Widely used frameworks at the moment are PyTorch and TensorFlow, thanks to their mature ecosystems and support for both research and production. On top of these, higher-level tools and model-serving solutions exist that simplify deployment. The choice depends on your existing infrastructure, required scale and team expertise.
How can bias in a deep learning model be detected and mitigated?
Detection starts with dataset analysis, stratification and fairness metrics. Technical mitigations include data augmentation, re-weighting of training samples and adversarial debiasing. Governance measures such as independent audits and transparent documentation of dataset and model choices are essential to reduce risks structurally.
What role do transformer models play in modern deep learning applications?
Transformer architectures have revolutionised natural language processing and are now also used in multimodal and vision tasks. Thanks to their attention mechanisms, transformers can model long-range relationships and scale to very large models. They form the technical foundation for many pre-trained models deployed in production and are often the first choice for tasks that require contextual understanding.
What practical steps can an organisation take to get started with deep learning?
First validate the business case and assess data availability. Next set up a proof of concept with a small team, leveraging pre-trained models where possible. In parallel with technical development, put governance in place, including privacy requirements and monitoring. For guidance on implementation and prototyping there are also external workshops and consultancy options; an example of such services can be found on the Spartner page about AI workshops. 🙂
How is the quality of a deep learning model assessed in production?
Quality is measured on task-specific metrics, supplemented with monitoring of performance characteristics such as latency and error rates. Post-deployment monitoring for data drift, performance degradation and user feedback is an integral part of quality assurance. Automatic retraining and alerts on anomalies are recommended operational measures.
Are there ready-made solutions for companies without an in-house ML team?
Yes, managed AI services and pre-built solutions exist for many common use cases such as image classification, transcription and sentiment analysis. For bespoke applications it is often best to start with a limited integration of pre-trained models and expand step by step, with external expertise helping with architectural choices and governance. See also the overview of AI automations on the Spartner site, including AI solutions for content production and service desk automation, via the AI content creation page and the AI email service desk development page.