Overview
Retrieval-augmented generation, commonly shortened to RAG, is a method for equipping large language models with current, domain-specific knowledge without retraining the model itself. It combines information storage, retrieval and text generation in a single coherent pipeline.
RAG is widely used for search-driven chatbots, help documentation, customer service, legal and medical question answering, and analytics on private data. Instead of relying solely on the statistical patterns baked into its training data, the model can fetch relevant documents during the question-answer cycle and use them as a factual foundation.
This article explains the key concepts behind RAG, including the basic architecture, the retrieval process, the role of vector databases and embeddings, how it interacts with large language models, different RAG variants, and the main quality and safety considerations.
Definition and positioning of retrieval-augmented generation
Retrieval-augmented generation is an architectural pattern in which a generative language model is given explicit access to external knowledge sources while answering a question. That knowledge may include documents, web pages, manuals, e-mails, product catalogues, code bases or other structured and unstructured data. The core idea is that the model does not answer solely “from memory” but first retrieves relevant information and uses it as context while generating text.
In a classic generative AI setting the model receives a prompt and immediately produces an answer, drawing all knowledge from its parameters. In RAG, a retrieval step is inserted between prompt and answer. This step searches a separate storage layer for pieces of information relevant to the question. The retrieved fragments are then appended to the prompt sent to the language model, enabling answers that better reflect the up-to-date, domain-specific facts contained in the documents.
RAG is often positioned as an alternative or complement to fully fine-tuning a model with new training data. Instead of retraining the model with large volumes of company data, the documents remain outside the model. The combination of a retrieval layer and a generative model forms the overall system. This has important consequences for maintenance, scalability, privacy and the speed at which knowledge can be updated.
A practical application of this architecture is a knowledge-based chatbot that searches internal documentation and policy texts. The chatbot receives the user’s question, searches the document collection for related passages, injects those passages as context and then generates an answer. In many modern enterprise solutions this RAG approach is integrated into existing web applications, for example built with Laravel or other web frameworks.
Core architecture and data flow in a RAG system
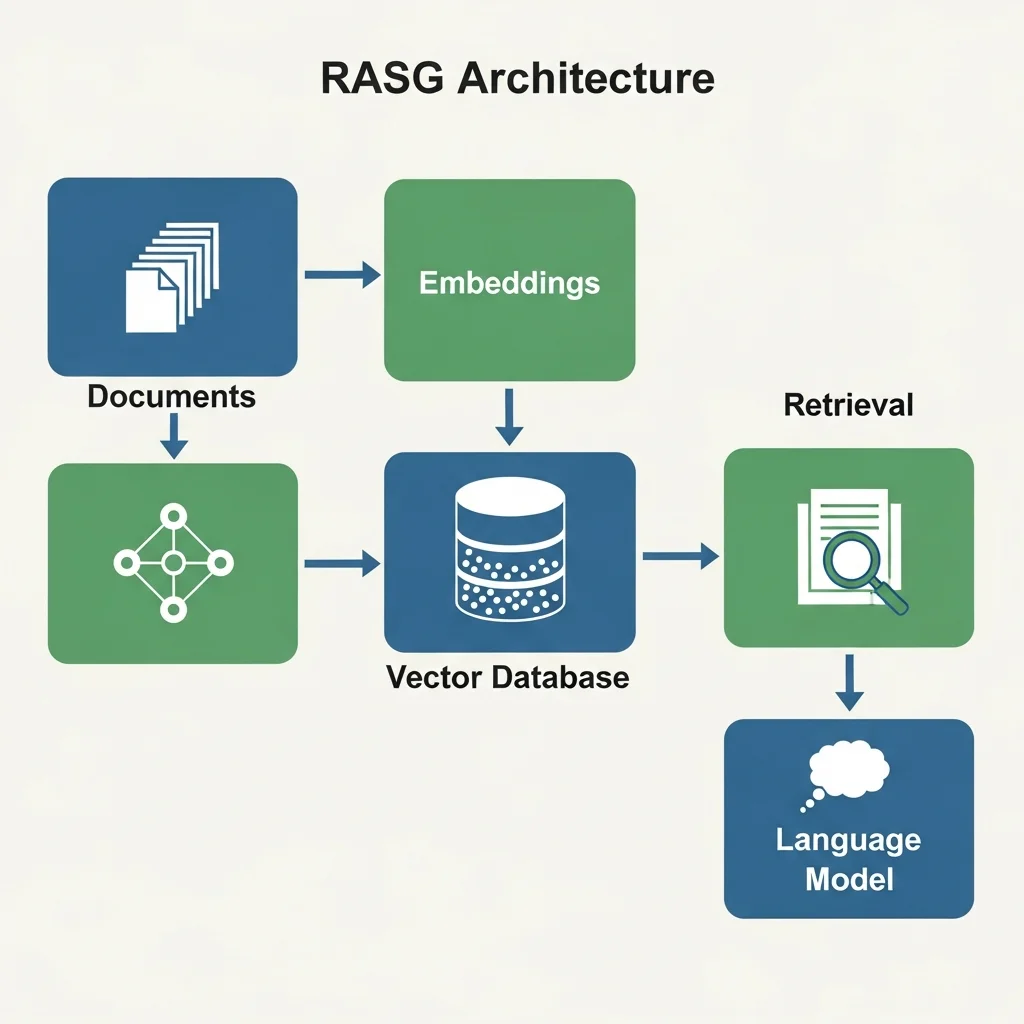
A RAG system consists of several building blocks that together define the data flow from question to answer. The core components usually include a document source, a pre-processing and chunking layer, an embedding model, a vector index or vector database, a retrieval and ranking layer, and a generative language model. Additional layers for logging, evaluation, safety and monitoring are often added.
The typical data flow starts with the documents. Text sources are gathered, cleaned and split into smaller text blocks, often called “chunks”. The goal is for each chunk to carry enough meaning on its own and not be too long for efficient storage and later context injection. The chunks are then converted into vectors via an embedding model—numerical representations that capture semantic similarities between texts.
The vectors are stored in a vector database or another form of index that supports fast similarity search. At that point the basis for retrieval is in place. When a user asks a question, the question is also turned into a vector via the same or a compatible embedding model. This query vector is used to search the index for the most similar document vectors, and the corresponding text chunks are returned as candidates.
A re-ranking or filtering step often follows, applying additional logic based on metadata, timestamps, access rights or domain rules. The selected documents are combined with the original question into an extended prompt that is sent to the generative language model. The model generates an answer, attempting to weave in the information from the retrieved documents. An important design principle is to instruct the model explicitly to stick to the supplied sources and to express uncertainty if the sources do not provide a clear answer.
A common variation is multi-turn conversation, where not only the current question and retrieved documents but also parts of the conversation history are included in the context. Such systems must carefully decide which parts of the chat history stay in the prompt and which are stored solely in the vector index. Access to multiple knowledge domains—say, general encyclopaedic knowledge alongside highly specific company information—can be handled through multiple indices.
RAG variants and related concepts
Several flavours of retrieval-augmented generation cater to different data types, tasks and architectural preferences. A first distinction is between “naïve RAG” and more advanced pipelines. In the simplest form, only the top N documents based on vector distance are retrieved and dropped straight into the prompt. More mature variants use a cascade: a broad initial retrieval followed by re-ranking, query expansion or logical filtering.
A key variant is hybrid retrieval. This combines vector search technology with classical methods such as inverted indices, keyword ranking and Boolean filters. By merging, for example, BM25 and vector search results, the robustness of the retrieval layer can be improved—especially in domains with short queries or specialist terminology. Some systems let the language model first craft a better search query before performing the actual retrieval.
There are also domain-specific RAG variants for fields such as healthcare, law, engineering and finance. These often apply extra rules to control the output. One example is a variant in which the generated text is compared with the source passages afterwards. If the answer cannot be sufficiently traced back to the sources, it can be rejected or flagged as uncertain. This approach is sometimes called “grounded generation” because the output is explicitly grounded in concrete sources.
RAG is further related to concepts like retrieval-based question answering, open-domain QA and context-augmented generation. What sets modern RAG architectures apart is their tight coupling with large language models and the use of embeddings for semantic search. Together, these techniques allow systems to produce natural-language answers while grounding them in corporate documents and other private data.
Benefits, limitations and quality considerations
RAG offers several advantages over generative systems that rely solely on model parameters. A major benefit is the separation of knowledge management and model management. New documents can be added to the index without retraining the language model, enabling frequent updates to the knowledge base—crucial in domains where information changes rapidly, such as legislation, product documentation or medical guidelines.
A second benefit is that RAG can help reduce “hallucinations”, the phenomenon where a model produces plausible-sounding but factually incorrect information. By explicitly feeding the model relevant source passages, the likelihood of accurate answers increases. Systems can also be configured to show the sources used, boosting transparency and verifiability—important for users who wish to check or explore the answer further.
There are, however, limitations and caveats. The quality of a RAG system strongly depends on the quality of the underlying documents and the strategy for segmentation, indexing and ranking. Poorly structured or outdated documents can lead to incorrect or incomplete answers. The embedding model matters too: if it does not grasp domain-specific terms well, the retrieval layer may miss relevant passages. There is also the context limit of language models—only a limited amount of text can fit into the prompt—so careful selection and summarisation of documents is required.
Quality assurance in RAG systems usually involves evaluation on multiple levels. Retrieval quality is measured, for instance, with recall and precision, while answer quality may be assessed through human ratings or task-specific metrics. In sensitive domains such as healthcare and legal advice, a human is often kept in the loop, with RAG acting as decision support rather than an autonomous decision-making system.
Finally, privacy and data protection are vital. Because RAG systems often access confidential business documents, data must be stored securely and only be available to authorised users. Systems can be set up so the language models do not reuse data for their own training. Policy documents and technical measures are also commonly applied to prevent sensitive information from leaking in answers.
What is retrieval-augmented generation in plain language?
Retrieval-augmented generation is a technique where a language model first looks up relevant information in a document collection and then uses that information to craft an answer. Instead of relying entirely on its internal knowledge, the system blends search and generation into one workflow. This often makes answers more up-to-date and easier to trace back to their sources.
How does RAG differ from a classic chatbot without a retrieval layer?
A classic chatbot relies on the model’s internal knowledge and possibly fixed dialogue rules, without fetching additional documents during the conversation. RAG inserts a separate search step, retrieving documents that match the specific question. As a result, a RAG chatbot can directly quote manuals, policy documents or product information and deliver answers that better align with the available knowledge.
Why is RAG widely used for corporate documentation and knowledge bases?
Information in organisations changes frequently—new procedures, products or legislation. With RAG the central documentation can stay up-to-date while the language model remains unchanged. By adding documents to the index, the system automatically gains access to new knowledge. This is more efficient than retraining the model each time and reduces the risk of staff working with outdated information.
Is RAG enough to completely prevent a language model from hallucinating?
RAG can significantly lower the chance of hallucinations but does not eliminate them entirely. The language model is still probabilistic and can make mistakes, for instance if the retrieved documents are incomplete or ambiguous. In practice, extra safeguards are used, such as instructing the model to say "I don’t know" when uncertain, post-processing checks and sometimes human review for critical decisions. 🙂
What role does a vector database play in a RAG architecture?
A vector database stores and searches the numerical representations of text—the embeddings. This allows the system to search on semantic similarity, not just exact keywords but also related concepts. When a question arrives, an embedding of that question is created and compared with the document embeddings. The documents with the most similar vectors are sent to the language model as context. Without such a vector index, semantic search on large text collections would be far less efficient.
What types of data can be used in a RAG system?
In principle any text form can be used, provided it is converted into searchable text. This may include web pages, PDF documents, e-mails, chat logs, code snippets, product catalogues or knowledge articles. More advanced systems also incorporate tables, chart descriptions or structured databases. These diverse sources are often standardised and enriched with metadata so the retrieval layer can filter and rank more effectively.
Is RAG only relevant for large organisations with lots of data?
RAG is certainly useful for large organisations with extensive document collections, but smaller organisations can benefit as well. Even with a relatively modest set of documents, a RAG system can provide consistent, easily retrievable answers to frequently asked questions. The scale of implementation differs, yet the underlying principle—combining search and generation—remains the same. For smaller setups, keeping the configuration simple and maintainable is key.