AI private data, trust and clever alternatives
Having doubts too?
What does "no training" actually mean?
OpenAI, Google, Microsoft and xAI promise not to train on your data—provided you disable the relevant checkbox.
Running your own LLama instance on-prem removes the data-escape risk, but still costs a bit of accuracy.
Trusting cloud AI tools is similar to the faith we have long placed in Office 365 and Google Workspace.
Spartner's Mind AI platform helps you pick the right LLM track without data loss or vendor lock-in.
Practical insights you can take away:
Checklist to validate AI providers’ privacy claims
Decision matrix: cloud model vs on-prem model
Tips for running a hybrid set-up (best of both worlds)
Concrete pitfalls from our own practice 🚧
Trust or verify?
The data owner is always responsible
Provider-promise Many vendors claim: "We don’t train on API data". Check whether this is the default or requires opt-in/opt-out. Scope: model training only, or logs as well?
On-prem option You can run LLama models (2 and more recently 3) on-device, so data never leaves your network. Downsides: more maintenance, often less up-to-date.
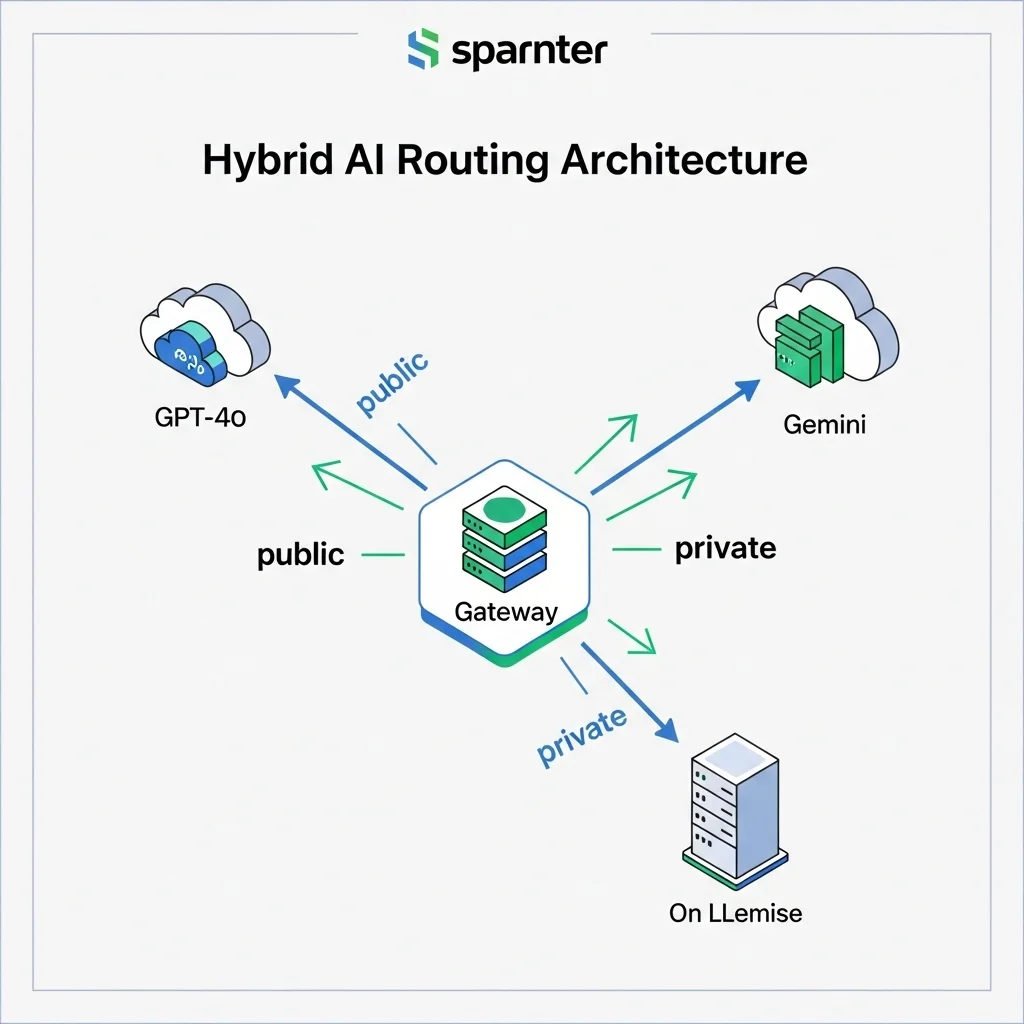
Hybrid path Combine public high-end models for generic prompts with local LLama for sensitive context. Automating the routing is key.
Governance first Define policy before you write prompts. Who may send what? How long are transcripts stored? End-to-end encryption?
Take stock and validate: the steps
Inventory your data classes
What is public, internal, confidential, strictly confidential?
We use a simple label matrix that ends up colour-coded in the prompt.
Validate provider claims
Run a local LLama pilot
Measure the quality gap
Build a hybrid router
Our approach: a lightweight API gateway that routes to GPT-4o, Gemini 1.5 or LLama-3-70B-Instruct based on data label and prompt type.
Gotcha: don’t forget log sanitisation!
Curious which route fits your data strategy best? Drop your question below or schedule a coffee chat—I’m happy to think along ☕.
The Big Four's privacy statements
Fine words, but what does the small print say?
OpenAI – Since March 2023, OpenAI no longer trains on API data. ChatGPT data is still used for fine-tuning unless you untick "Chat history & training" in settings. In the Enterprise licence it is off by default.
Microsoft – In Azure OpenAI it’s "your prompts, your completions, your data". Data stays in your tenant, is not used for model training and is logged for fourteen days for abuse monitoring—encrypted at rest.
Google – Gemini 1.5 claims not to include enterprise data in its training pipeline. The company does collect live metrics, but they are anonymised.
xAI – Rising star Grok focuses on public X data. Customer API data ends up in a silo with no read rights for the training team, according to their white paper of July 2025.
"LLM safety equals cloud trust. If you’ve trusted SharePoint for years, this is technically the same trust—only with a more powerful content processor behind it."
LLama locally: less shine, more control
What does running your own server really get you?
Recently we ran LLama-3-8B on a Mac Studio to generate marketing copy for an internal campaign. The result? Acceptable, but not dazzling. The same prompt sent to GPT-4o came back with nuances and cultural references LLama missed.
The trade-off:
Security: Data never leaves your LAN, so no DPA headaches.
Performance: Heavier model? Then a bigger GPU budget and higher energy bill.
Maintenance: Patch, update and apply quantisation tricks yourself.
Quality: LLama 3-70B approaches GPT-3.5, but GPT-4o level is still far away.
A comfortable middle ground is quantised LLama 3-13B (Q4-K). It runs on a single high-end GPU and in our tests scores 82 % of GPT-4o on factuality for technical Q&As—good enough for internal knowledge bases.
Hybrid architecture in practice
How we solve it for clients
We built Mind AI so every prompt first passes through a sensitivity classifier. Score above the threshold? Then route to local LLama; otherwise to a public API. Logs are stored in an encrypted vector database with a twelve-hour retention.
```php
$route = classify($prompt);
switch($route){
case 'private': return llama_local($prompt);
case 'public': return gpt4o_cloud($prompt);
}
```
This lets you enjoy the best of both worlds without constantly jumping between tools.
Business perspective: what does trust cost?
Risk, reputation and ROI
Organisations invest millions in ISO certificates to win customer trust. Yet employees still casually paste sensitive info into ChatGPT. Policy alone isn’t enough; tooling has to think along.
Shadow AI emerges lightning-fast. A ban backfires; facilitation works better.
ROI on an on-prem model only turns positive once you send thousands of prompts a day.
Compliance pressure (NIS2, DORA) accelerates the need for audit trails within LLM workflows.
Strategic tip: Don’t just count GPU costs; also weigh the value of faster decision-making via high-end models. Extra data protection can pay for itself in a single incident that never happens.
Can I use OpenAI for privacy-sensitive data if I untick the box?
Yes. Technically your prompt won’t enter the training set. In our experience the biggest risks after that lie in log retention and human error.
Is a local LLama always safer?
Not necessarily 😊. Without solid network segregation, an on-prem model can expose more attack surface than a tightly managed cloud tenant.
How big is the quality gap between GPT-4o and LLama-3-70B?
In our benchmark set (500 NL/EN prompts) GPT-4o scored 94 % on factuality, LLama-3-70B 86 %. Fine for brainstorming, too low for legal advice.
Do I need a separate DPIA for every model?
Not per se. You can run an overarching Data Protection Impact Assessment and include a risk profile per model—saves paperwork.
What about latency with local models?
With a modern GPU, LLama-3-13B sits at around 1 s per 250 tokens. Via the cloud you get 250-500 ms. Whether that’s acceptable depends on your use case.
What if the policies change tomorrow?
Set WAF rules and alerts on your provider’s policy URLs. That way you’ll spot changes within an hour. We do this ourselves with a simple diff checker 👀.
Can I add my own data to a cloud model without it leaking?
Yes—via "retrieval-augmented generation" (RAG). You keep the data in your vector DB; the model only sees embeddings in context.
How does Spartner help with this?
We offer Mind AI, a platform where you can switch between GPT-4o, Gemini, LLama or Grok with one click—plus a built-in governance layer that handles audit logs and data classification.
I’d love to hear how you balance cloud convenience and on-prem control. Share your thoughts below or book a sparring session—the coffee’s ready! ☕