In 2025, AI chatbots are no longer a futuristic luxury but a down-to-earth growth engine for SME entrepreneurs. In this guide I take you step by step from the first idea to a live bot, sharing fresh insights from the very latest AI developments and lessons from our own practice.
Can your business already talk?
In 2025, AI chatbots are no longer a futuristic luxury but a down-to-earth growth engine for SME entrepreneurs. In this guide I take you step by step from the first idea to a live bot, sharing fresh insights from the very latest AI developments and lessons from our own practice.
Talk or sink
Why start now
2025 forces conversation
Growth accelerator Sales and support processes have sped up by an average of 38 % since GPT-4o bots arrived. Less waiting time means more repeat purchases.
Customer expectation According to Zendesk's 2025 Trends Report, 71 % of consumers expect 24/7 chat support, even from local webshops.
Cost saving Automation can shave up to 30 % off support costs. Beware though: the wrong implementation will actually add costs.
Data goldmine Conversations provide raw customer insights you would never get from surveys. A smart bot logs and labels all of it automatically.
The 2025 playing field
GPT-4o, Gemini & Llama: choice overload or opportunity?
The other day I spoke with an entrepreneur in the construction sector who thought a "little ChatGPT script" would do the job. Understandable—the hype is loud. But reality? Each model has its own quirks.
GPT-4o
Multimodal: understands text, images and speech.
Ideal for webshops that want product photos recognised.
Google Gemini 1.5
Meta Llama 4 (open-source)
Pro-tip: Test the same prompt on two models and measure conversion or resolution rate. Choose data-driven, not by brand name.
No-code versus custom build
No-code platforms (think Chatlayer, ManyChat, Intercom Fin) can have you live within days—perfect for validation. But as soon as you need ERP integrations or multilingual flows, no-code stalls.
What we usually do is hybrid:
Rapid prototype in no-code.
Analyse logs & intent patterns.
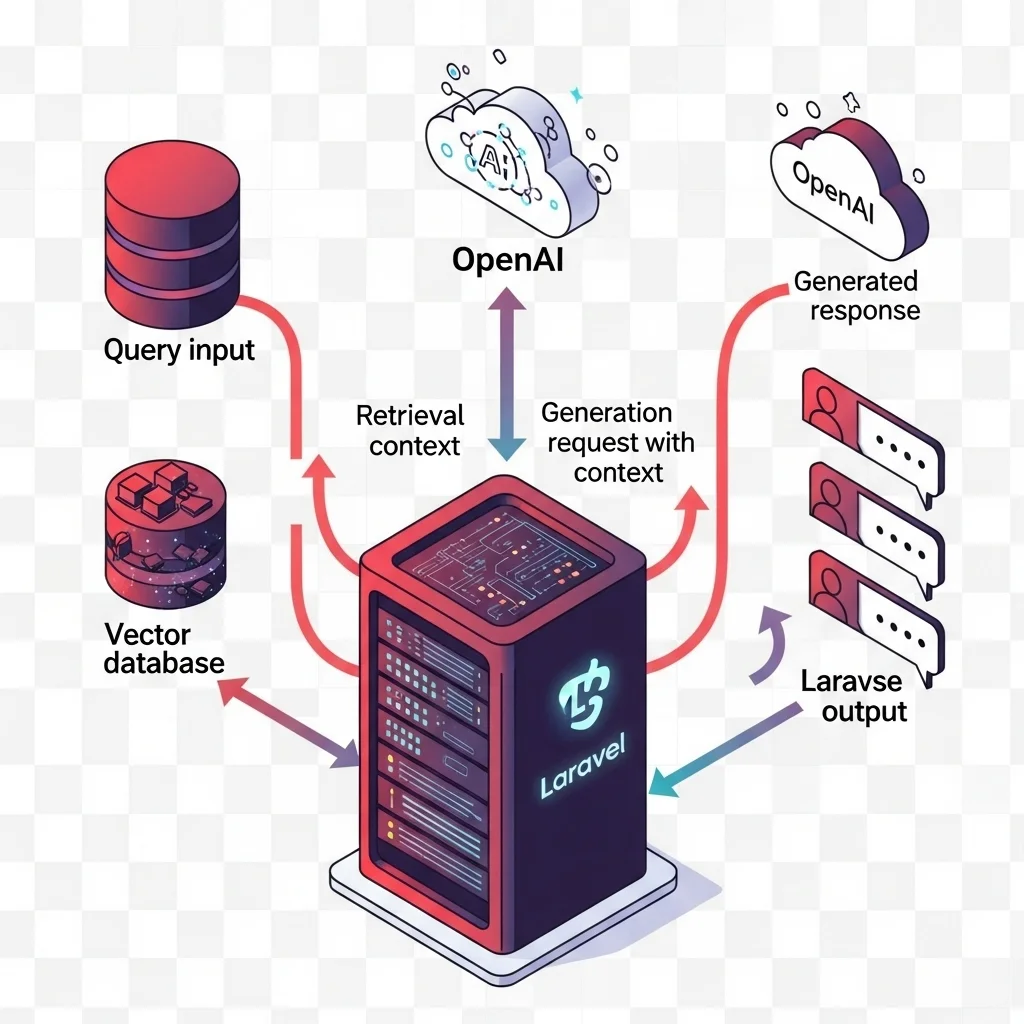
Migrate to a Laravel micro-service with the OpenAI API + a RAG layer.
Strategic preparation
Down with the 'does-it-all bot'
Ever wondered why some bots get switched off after week three? They try to solve everything at once. Pick one razor-sharp goal: lead qualification, returns handling or internal IT support.
H4 User story first
"As a visitor hesitating between size M and L, I want instant sizing advice." Write ten such stories, prioritise them, and build only the top three.
H4 Data sourcing
The interesting thing is that RAG (Retrieval Augmented Generation) is now ridiculously easy thanks to vector databases like Qdrant or LanceDB. Drop your FAQ docs in a bucket, index, done. But:
H4 Personality design
Imagine your accountant cracking jokes—awkward, right? Define tone, jargon and taboo words. Capture them in system prompts.
From idea to live in 5 steps
Choose the problem
Prototype within 48 hours
RAG & integration
Security & compliance
Activate profanity filters.
Log all prompts anonymously in BigQuery.
Check the EU AI Act high-risk criteria.
Launch & learn
Tech deep-dive
How do you build a Laravel-powered RAG service?
// Simplified embedding workflow
$client = new OpenAI\Client(env('OPENAI_KEY'));
$chunks = TextSplitter::make($pdf)->chunks(800);
foreach($chunks as $chunk){
$embedding = $client->embeddings()->create([
'model' => 'text-embedding-3-small',
'input' => $chunk
])->vector;
VectorDB::upsert($embedding, ['chunk' => $chunk]);
}
Plus, with Laravel Octane + RoadRunner you can effortlessly handle 1,000 req/s. What I notice in practice: I/O wait is your bottleneck, not the GPU. Cache embeddings locally and use streaming responses for a snappier UX.
Business impact & metrics
What should you really steer by?
In our experience, FCR correlates most strongly with customer satisfaction. A bot that stumbles costs you reputation points. So don't just measure how many chats it takes over, but also how often it resolves them flawlessly.
Handy tip: add a quick emoji rating 👍👎 under each bot reply. The threshold is lower than a 5-point scale and yields three times more feedback.
Looking back
From hype to hard cash
Chatbots have grown up. The latest trend shows that generative models no longer just spit out answers but execute entire workflows. As an entrepreneur you can now get started without a million-euro budget, as long as you stay laser-focused on the problem, data quality and feedback loops.
Key takeaways:
Start small, scale smart.
Combine no-code speed with custom power.
Measure what matters, not what looks nice.
Privacy-by-design prevents nightmares later on.
Why not just stick ChatGPT on my site?
In our experience a naked widget delivers about 60 % irrelevant answers because it lacks your business context. RAG and gating prompts make all the difference. 😅
How much training data do I need?
Quality over quantity. With 100 well-structured Q&A pairs and a vector DB you can already go live—but keep adding weekly.
Is open-source (Llama) safe enough?
Yes, as long as your model doesn't leak to the outside. On-premise hosting means patching and monitoring yourself—something many SMEs underestimate.
How much does a GPT-4o call cost?
Since June 2025 the price dropped to $5 per million tokens. Peak hours are still a cost risk, so buffer with a fallback to GPT-3.5-Turbo.
Can my chatbot provide multilingual support?
Absolutely. GPT-4o performs at near-native level in 30+ languages. Do log language statistics so you know which content localisation should be prioritised. 🌍
How do I prevent hallucinated answers?
Clarify the system prompt: "Answer only based on the knowledge base."
How do I integrate WhatsApp Business?
Use Meta's Cloud API. Mind the 24-hour session rule: after a day you need an HSM template to reply.
Can I start without a developer?
For an MVP, yes. But once you want ERP, CMS or CRM integration, a dev team is indispensable. 😉
Curious to see how your idea translates into a smart bot? Leave a comment or schedule a virtual coffee. Always happy to spar about conversational AI and discover where your business can reap the biggest gains! 🚀