Machine learning is a branch of artificial intelligence that enables computers to learn patterns from data and make predictions without explicit rules. This knowledge-base article explains the core concepts, workflow, key application areas and recent developments in a business-oriented way.
Summary
Have you ever wondered how systems can make reliable predictions without being explicitly programmed to do so? Machine learning is the branch of computer science that makes this possible by training statistical models on examples instead of writing rules.
Key takeaways
Definition and position within AI, including the distinction from traditional software development.
Most important types of machine learning, typical algorithms and a concise training process.
Practical applications, evaluation criteria and common risks such as bias and data leakage.
Recent developments and relevance for modern LLM-driven solutions, with references to current discussions about model quality and governance.
Actionable insight
For a responsible project kick-off, start with a clear data audit and business objective, choose an appropriate model class, and explicitly define metrics for success.
What is machine learning
Machine learning is a discipline within artificial intelligence that focuses on developing algorithms that learn from data. Instead of hard-coding every decision, a model optimises parameters based on examples so it can make predictions or classifications on new, unseen data.
The distinction from traditional software engineering is important. In conventional systems a developer writes the rules; in machine learning those rules are derived from patterns in the training data. This makes it possible to solve problems that are too complex for hand-crafted rules, such as image recognition and speech transcription.
In a business context, machine learning is a tool for quantifying uncertainty and supporting decisions. Successful deployment requires reliable data, clear KPIs and governance to control risks such as data contamination or unintended bias.
How does machine learning work technically
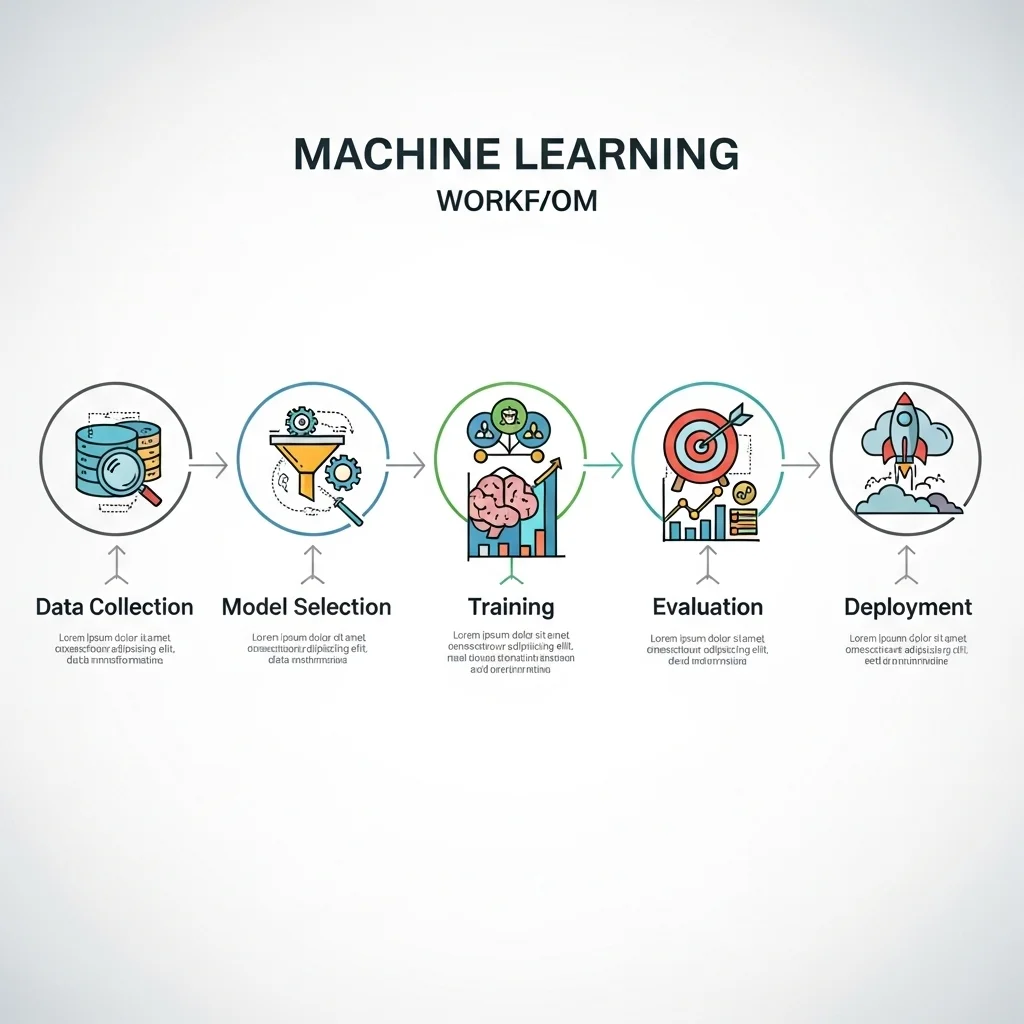
The basic machine-learning workflow consists of data collection, preprocessing, model selection, training, evaluation and deployment. Data preprocessing includes normalisation, handling missing values and feature engineering, because raw data is rarely suitable for model training straight away.
Models range from simple linear regressions and decision trees to advanced neural networks and transformer architectures. Supervised learning uses labelled examples, unsupervised learning searches for structure without labels, and reinforcement learning trains agents through rewards. Evaluation makes use of metrics such as accuracy, precision, recall, F1-score and, for regression, RMSE or MAE, depending on the use case.
The following concise training example in pseudocode shows the core steps of a supervised workflow:
data = load_dataset('train.csv')
features, labels = preprocess(data)
model = initialize_model('random_forest')
for epoch in range(1, N_epochs+1):
batches = create_batches(features, labels)
for X_batch, y_batch in batches:
model.train(X_batch, y_batch)
metrics = evaluate(model, validation_set)
deploy_if_satisfactory(model, metrics)
This illustrates that the process is iterative and that evaluation on an independent validation set is essential to detect overfitting.
Applications, limitations and recent developments
Machine learning is applied in a wide range of domains, including healthcare, financial services, legal tech and manufacturing. Typical examples are predicting customer behaviour, detecting fraud and automatically analysing documents. Inside organisations it is important to adopt modular architectures so that models are reproducible, auditable and updateable.
There are clear limitations. Model bias, insufficiently representative data and unclear extrapolation outside the training distribution are real risks. Explainability is also crucial in regulated sectors. Governance and data ethics must be integral to every project.
Recent developments focus on scalability, model safety and explainability. There is lively debate about the role of large language models in operational systems, including quality control and privacy. During the past week trade media and academic platforms have highlighted evaluation practices and responsible use of large models, and Spartner's own site recently discussed expectations for upcoming LLM releases in the article about Claude 4.5, which is relevant for organisations embedding LLM capabilities. For companies looking to kick-start their AI and machine-learning journey, the pages Starting with AI and Creating AI content are additional resources.
What is the difference between machine learning and classical statistics?
Machine learning and classical statistics share many methods but emphasise different aspects. Statistics focuses on inference and explanatory models, often with explicit assumptions. Machine learning pays more attention to prediction and scalability, with a strong emphasis on performance on new data. In practice the two disciplines complement each other.
Which types of problems are suitable for machine learning?
Problems with sufficient structured data and a clearly defined target for prediction or classification are suitable. Typical examples are churn prediction, image classification and text classification. Problems lacking enough data or with extremely high verification requirements are better tackled with traditional software or additional data governance.
How is the quality of a model measured?
Quality is measured with data- and domain-specific metrics. For classification, precision and recall are relevant when classes are imbalanced. For regression, RMSE and MAE are used. Out-of-sample validation is crucial, and techniques such as cross-validation, hold-out sets and A/B tests are common tools. A separate evaluation on production-like data is often the most valuable.
Which ethical and legal risks apply to machine learning?
Key risks are bias in the training data, a lack of transparency in decisions and the privacy of personal data. Regulations such as the GDPR require careful data processing, and in certain sectors there are explicit demands for explainability and auditability. Implementing logging, data lineage and consent management belongs to the best practices.
Should a company build its own models or use off-the-shelf LLMs?
The choice depends on the use case, data sensitivity and the required level of control. For standard tasks, using existing LLMs or model APIs can be efficient. For sensitive data, bespoke functionality or compliance requirements, a proprietary model or private hosting is often advisable. For organisations wanting to experiment, steps such as a data audit and a proof of concept are recommended.
How do you ensure the safe, controlled deployment of ML models?
Safe deployment requires a combination of technical and organisational measures, such as model monitoring, retraining strategies, rollback procedures and access control. It is also crucial to define clear acceptance criteria and to set out the impact on business processes. Governance around data quality and logging forms part of compliance.
What recent trends are relevant for machine-learning projects?
Recent focus points include better evaluation metrics for generative models, tools for model explainability and frameworks for model governance. Technical communities and the trade press emphasise the robustness of LLMs in production environments and methods for detecting drift in model performance. Organisations integrating LLM functionality are advised to document explicitly which model versions and datasets are used and to validate frequently against realistic scenarios. 😊