Overview of natural language processing
Natural language processing is a sub-field of artificial intelligence that enables computers to analyse, understand and generate human language. It is used in search engines, chatbots, automatic translators and generative AI models, among other applications.
This article systematically explains the key concepts, techniques, models and applications of NLP. Recent developments such as large language models and retrieval-augmented generation are covered, as well as their limitations and issues around privacy, bias and reliability.
Key take-aways in this article:
Explanation of the basics of NLP and how it differs from broader AI and machine learning
Historical overview of symbolic systems, statistical models and deep learning
Description of core techniques such as tokenisation, tagging, parsing, embeddings and transformer architectures
Explanation of large language models and retrieval-augmented generation
Overview of typical applications, from search engines to legal and medical text analysis
Main challenges, including hallucinating models, bias, safety and regulation
Definition and position of natural language processing within AI
Natural language processing, often shortened to NLP, is the branch of artificial intelligence focused on enabling computers to process human language. The goal is for systems to analyse, interpret, generate and reason with text and speech in useful ways.
NLP sits at the crossroads of computer science, linguistics and statistics. Computer science contributes data structures, algorithms and software architecture. Linguistics provides insights into grammar, semantics and pragmatics—how sentences are built and how context shapes meaning. Statistics and machine learning supply the methods for spotting and modelling patterns in large text datasets.
Within the wider AI landscape, NLP is one of the most important areas of application. Many generative AI systems are essentially NLP models trained to predict text. Speech systems combine NLP with speech recognition and synthesis. Language models are increasingly being used as general reasoning engines, even outside purely textual contexts.
Basic concepts in NLP
Several core concepts appear in almost every NLP application. Tokens are elementary units of text, such as words or word pieces. Tokenisation is the process of splitting raw text into these tokens. A corpus is a large, often carefully curated collection of text used to train and evaluate models. Labels are the categories a model learns to predict, such as the language of a text, its sentiment or the grammatical role of a word.
Another key distinction is between supervised and unsupervised learning. In supervised learning, a model is trained on texts with known labels—for example, emails classified as spam or not spam. In unsupervised learning, a model searches for patterns in the data without direct labels, such as clustering similar words.
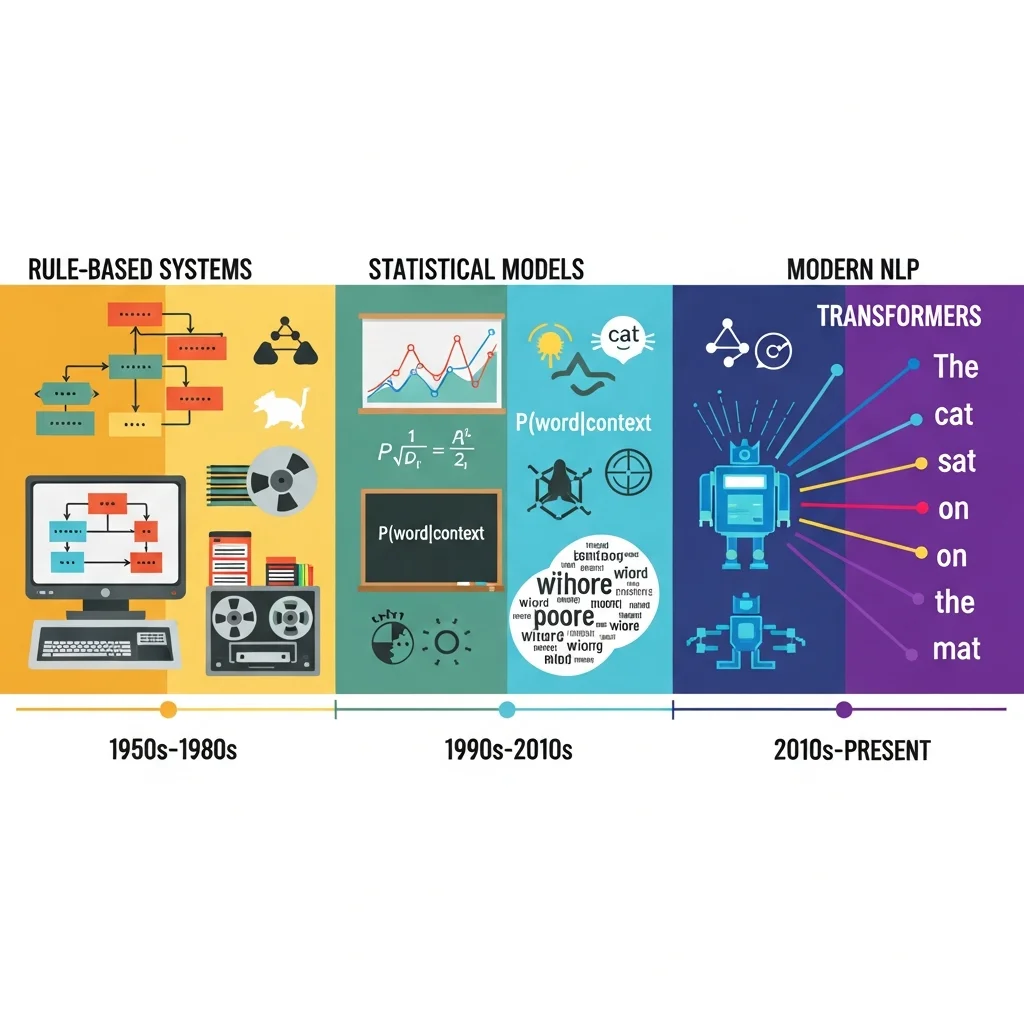
Historical development of NLP: from rules to large language models
The history of natural language processing is often divided into three main periods. The first period was dominated by symbolic or rule-based systems. In this approach, experts manually codified grammar rules, dictionaries and semantic structures. Early machine translation and grammar checkers relied on such rules, which resulted in limited coverage and poor scalability.
During the second period, the focus shifted to statistical NLP. Thanks to larger text corpora and faster computers, probabilistic models such as n-gram language models and Hidden Markov Models became common. These models learn probabilities of word sequences and labels from data. Applications such as automatic speech recognition and probabilistic part-of-speech tagging became more reliable, though they often remained relatively shallow in their grasp of context.
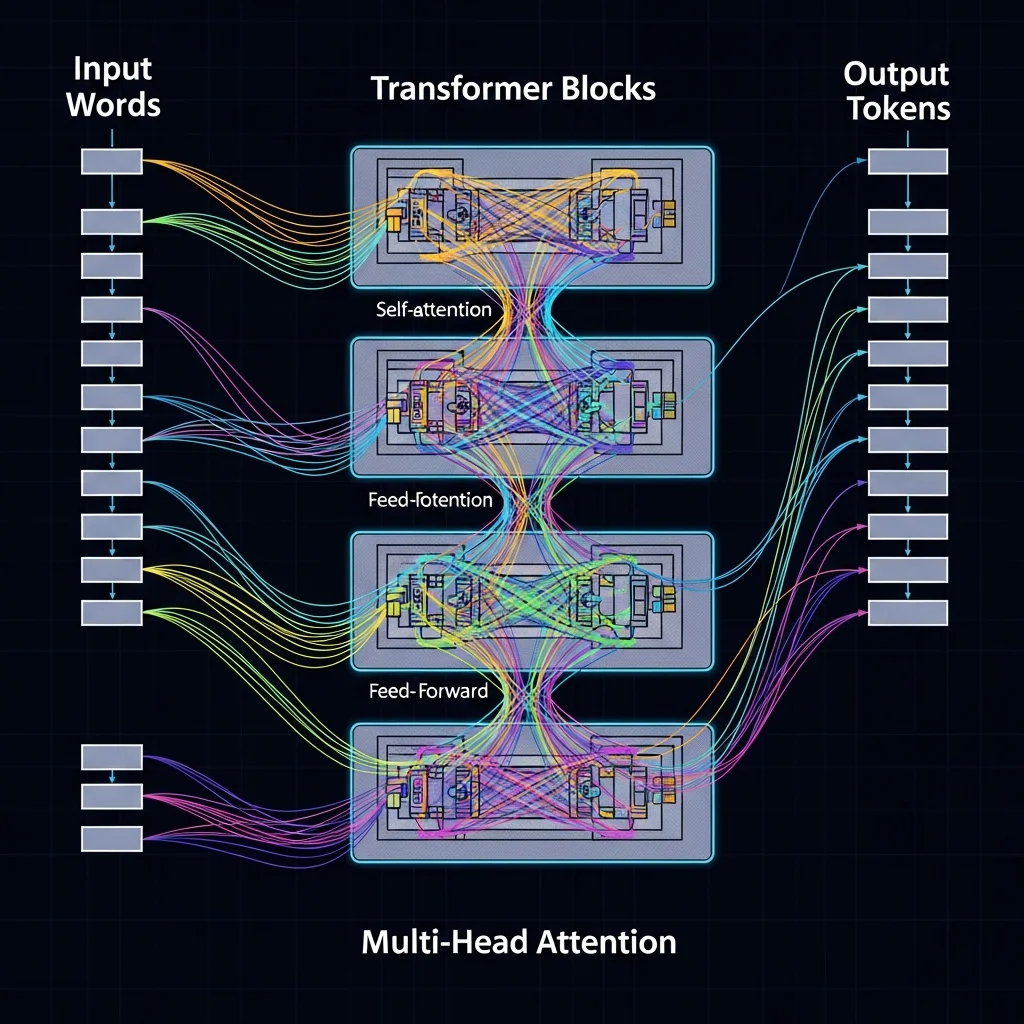
The third period, which is still ongoing, is characterised by deep learning. Neural networks were first deployed for specific tasks such as sentiment analysis or translation. The introduction of the transformer architecture—using attention mechanisms to learn relationships between words regardless of distance—enabled the training of large, general language models that can handle many NLP tasks at once.
A major recent step is the rise of so-called foundation models, often referred to as large language models. Trained on vast amounts of text—sometimes hundreds of billions of tokens—these models can generate text, answer questions, write code and perform tasks they were not explicitly trained for. Because they are generic and reusable, they form the basis for countless applications across sectors.
Architectures and representations
Modern NLP models revolve around representing language in a form suitable for computation. Simple models used bag-of-words approaches, merely counting how often words appear. Later techniques introduced word embeddings—vector representations in which words with similar meanings lie close together. Word2Vec and GloVe are well-known examples of such embedding methods.
Transformer-based models go a step further with contextual embeddings, giving a word a different vector representation depending on its context. The word bank, for instance, is represented differently in the context of a financial institution than in the context of a piece of furniture. This awareness of context delivers far better performance on complex language tasks.
Core techniques and typical NLP tasks
NLP encompasses a wide range of techniques and tasks. Many NLP pipelines start with text pre-processing. Tokenisation splits text into tokens. Normalisation converts text into a standard form, for example by lower-casing or removing diacritics. Stop-word removal can filter out common words like the, a and an when they carry little information for a given task.
A classic task is part-of-speech tagging, where each word in a sentence receives a label indicating its grammatical category—noun, verb, adjective and so on. This information is often used as input for more complex tasks such as syntactic parsing. Parsing reconstructs the grammatical structure of a sentence as a tree or dependency graph.
Semantic tasks focus on meaning. Named entity recognition identifies and labels entities such as people, organisations and locations in text. Coreference resolution determines which referring words—he, she, this company—relate to the same entity. Sentiment analysis estimates the attitude or emotions in text, for example positive, negative or neutral. Text classification assigns documents to predefined categories such as product reviews, legal texts or medical reports.
Most modern techniques are based on neural networks and are often implemented in deep-learning frameworks. A common pattern is to use a pre-trained language model and fine-tune it for a specific task. An example in code looks like this:
from transformers import AutoTokenizer, AutoModelForSequenceClassification\n\ntokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")\nmodel = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")\n\ninputs = tokenizer("This movie was surprisingly good", return_tensors="pt")\noutputs = model(**inputs)\nlogits = outputs.logits
In this example, an existing sentiment-analysis model is used. The tokenizer converts the text into model input, after which the model predicts a classification.
For a more visual introduction, there are online courses and lectures available. A popular lecture series is the introductory NLP class from an advanced course at Carnegie Mellon University, available on YouTube via this link: https://www.youtube.com/watch?v=MM48kc5Zq8A. These lectures cover typical NLP tasks, model architectures and evaluation methods in greater technical depth.
Large language models, RAG and current focus areas
Large language models currently dominate the NLP field. These models are trained with the simple yet powerful objective of predicting the next token in a text. By training on huge corpora, they learn language patterns useful for a wide variety of tasks. They power chat interfaces, code assistants, search systems, translators and many other applications.
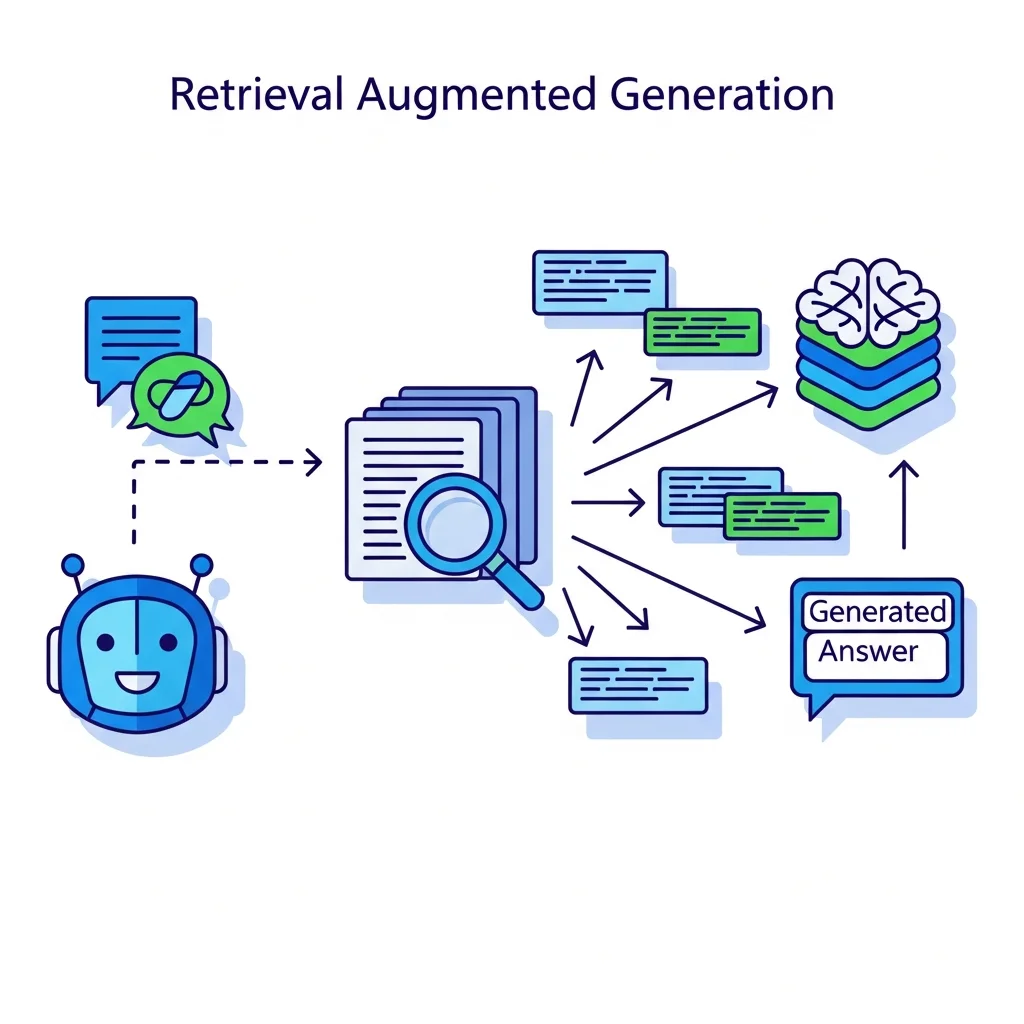
A major challenge with large language models is that they sometimes produce plausible-sounding but fabricated information—a phenomenon often called hallucination. Because the model learns patterns in text without direct access to factual databases, it can make mistakes in factual details, dates and numbers. Retrieval-augmented generation mitigates this by combining a language model with a search component that fetches relevant documents. The model then generates answers based on the retrieved context, improving reliability and traceability.
Alongside generative uses, analytical applications of NLP remain important. Here, the goal is not merely to produce text but to analyse it to extract insights—detecting brand sentiment on social media, identifying patterns in legal rulings or extracting clinical information from medical records. In such contexts, accuracy, reproducibility and explainability are critical quality criteria.
Several broader themes are becoming increasingly important when deploying NLP. First, there is the issue of bias and discrimination. Models learn patterns from the data they are trained on, and if that data contains prejudices or skewed representations, models can amplify them. Second, there are privacy concerns, especially in applications that process sensitive documents or conversations. Third, safety and misuse come into focus—for example, systems that can generate persuasive misinformation.
Regulation and best practices are evolving rapidly. Organisations applying NLP increasingly face requirements around transparency, auditability and data minimisation. Evaluation methods therefore no longer focus solely on accuracy or F1 scores but also on robustness, fairness and compliance with legal frameworks.
What exactly is natural language processing?
Natural language processing is the field within artificial intelligence concerned with enabling computers to process human language. It covers all techniques that allow systems to analyse, understand and generate text and speech, such as translation, text classification and question-answering systems.
How does NLP differ from general AI or machine learning?
Machine learning is an umbrella term for techniques that let systems learn patterns from data. NLP is a specific application area where the data is language—text or spoken words. Many NLP systems therefore use machine-learning methods but add linguistic knowledge and specialised model architectures to deal with the complexity of language.
Which typical NLP applications are used in organisations?
Common applications include automatic translation, chatbots and virtual assistants, sentiment analysis of customer feedback, search engines with semantic understanding and automatic summarisation of long documents. In sectors such as finance, legal, healthcare and government, NLP systems are also used for tasks like contract analysis, compliance monitoring, triage of dossiers and information extraction from reports and forms.
Why are large language models so important for NLP?
Large language models matter because they have learned language patterns at scale and can therefore perform many different tasks without each individual model having to be designed and trained from scratch. They act as a generic building block that can be adapted to a specific task with relatively little extra data. At the same time, they bring new challenges such as the risk of hallucinations, reduced explainability and the need to handle confidential data with care.
What is retrieval-augmented generation in the context of NLP?
Retrieval-augmented generation is an architecture that combines a language model with a search component. First, documents or passages relevant to a query are retrieved; the model then generates an answer based on this specific context. This helps ground answers in source material and can improve factual accuracy and traceability, provided the underlying document collection is carefully curated and maintained.
How is the quality of NLP systems measured?
The quality of NLP systems is measured with task-specific metrics. For classification problems, accuracy, precision, recall and F1 score are common. Translation uses metrics such as BLEU and COMET. For generative tasks, human evaluations play a major role—rating coherence, relevance and factuality. Increasingly, fairness, robustness and safety are also explicitly evaluated to better assess societal impact.
What risks and limitations do NLP systems have?
Key risks include biased output, factual errors, vulnerability to adversarial input and undesirable use, for instance to generate misleading content. Models also lack transparency, making it hard to understand why a particular answer was produced. These limitations mean NLP systems are usually deployed as support tools and that human oversight remains advisable for critical decisions.
How are NLP and speech recognition related?
Speech recognition converts spoken language into text, while NLP can then analyse and process that text. In a voice-controlled assistant these components are combined: a speech system first recognises the words, an NLP component interprets the meaning, a system decides on a response and speech synthesis delivers a spoken reply. Although speech recognition and NLP pose different technical challenges, they are closely intertwined in modern AI solutions.