Machine learning turns data into value without having to code every decision by hand. In this knowledge-base article you'll discover how the technology works, which learning paradigms exist and which recent breakthroughs explain its rapid rise.
Overview
Machine learning in three minutes
Machine learning is the discipline within artificial intelligence that teaches algorithms to recognise patterns and make decisions based on data. The field is advancing at breakneck speed thanks to powerful hardware, vast data collections and sophisticated neural networks. Recent examples, such as Google Gemini classifying astronomical images with only fifteen samples, underline the pace of innovation.
Key take-aways:
Definition, history and relationship with AI
Different learning types (supervised, unsupervised, reinforcement)
Concrete algorithms, from decision trees to transformer networks
Quality risks such as bias and overfitting
Emerging trends, including multimodal LLM systems and edge learning
Fundamentals and definition
Machine learning is an umbrella term for statistical methods that automatically find patterns in data and make predictions from them. The principle was introduced in 1959 by IBM researcher Arthur Samuel. Since then the technique has evolved into a core component of modern software, from spam filters to self-driving cars.
Historical context and relationship with AI
After pioneering work in the 1950s and 60s, attention shifted to neural networks in the 1980s. The major breakthrough arrived around 2012 when deep-learning models, powered by GPUs and datasets like ImageNet, achieved spectacular results. Machine learning is often viewed as a subset of artificial intelligence: AI is the broader goal of matching human intelligence, while machine learning focuses on data-driven learning techniques.
Learning paradigms and algorithms
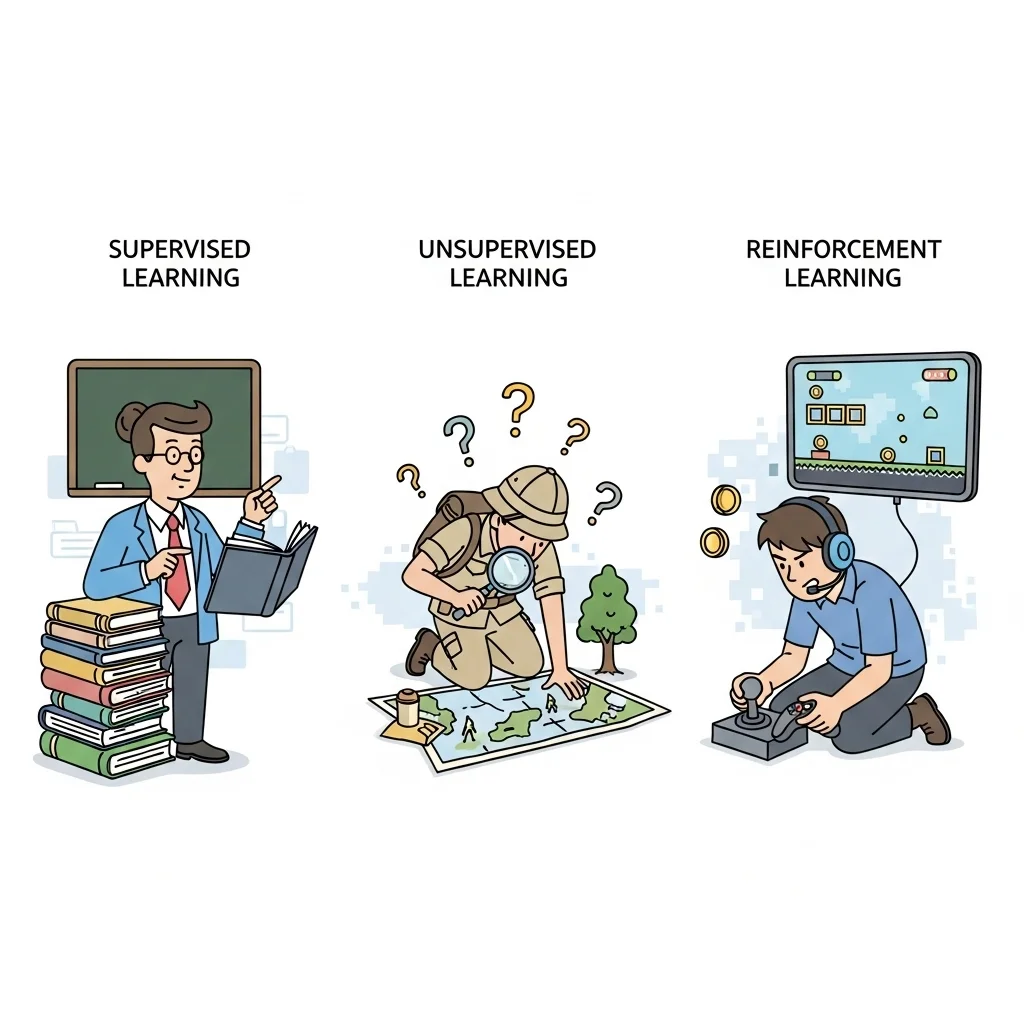
Every practical application relies on one of three learning strategies.
Supervised learning
Here the algorithm receives labelled examples (inputs with corresponding outputs). Models such as decision trees, random forests and neural networks belong to this category. They excel at classification and regression, for instance predicting churn or recognising images.
Unsupervised learning
When labels are absent the model seeks hidden structures. Clustering algorithms (k-means or DBSCAN) and dimensionality-reduction methods (PCA, t-SNE) uncover segments or compress complex data for visualisation.
Reinforcement learning
This method learns through rewards and penalties. It is successful in robotics and game AI. An agent optimises a sequential decision, similar to how a chess program improves through self-play.
Recent innovations and real-world cases
Machine learning is evolving thanks to better hardware, open-source libraries and new architectures such as transformers.
Multimodal LLM assistant in astronomy
On 8 October 2025 the University of Oxford and Google Cloud published a study in which Gemini, a general large language model, distinguished genuine astronomical transients from noise with 93 percent accuracy using only fifteen examples. The model also provided readable explanations for its choices, boosting transparency. This breakthrough shows that small datasets are no longer a show-stopper and accelerates "human-in-the-loop" workflows.
Edge and embedded learning
Thanks to specialised chips such as TPUs and neuromorphic hardware, models now run locally on devices. This enables real-time analysis in industrial environments or medical wearables.
Quality aspects and risk mitigation
Machine learning is powerful but not infallible.
Bias, overfitting and explainability
A model can make biased decisions if the training data are skewed. Overfitting occurs when the model memorises the training data and fails to generalise. Modern frameworks such as SHAP and LIME generate explanations and increase trust.
Governance and compliance
Legislation demands insight into decision logic, especially for high-risk applications. A structured AI-governance approach, as described in grip on AI governance, helps organisations embed ethical and legal requirements.
What is the difference between machine learning and artificial intelligence?
Artificial intelligence is the overarching goal of enabling computer-driven systems to act intelligently. Machine learning is a subset that uses statistical methods to learn from data.
How much data do you need to get started?
Practical experience shows that a few thousand labelled examples are often enough for tabular problems. For images and language the bar is higher, unless you use transfer learning or generic LLMs, as in the Gemini example from October 2025.
Which programming languages are most popular for machine learning?
Python dominates thanks to libraries such as TensorFlow, PyTorch and scikit-learn. In the Laravel world, PHP is combined with Python services to integrate models—see our approach to getting started with AI.
Can machine learning run locally on embedded hardware?
Yes. Frameworks like TensorFlow Lite and ONNX Runtime let you compress models and run them on microcontrollers. This is useful for IoT sensors where latency and privacy are crucial.
How is the quality of a model measured?
Common metrics include accuracy, precision, recall and F1-score. For regression problems MSE or MAE are used. In our experience it is vital to pair quantitative metrics with explainability checks to spot unexpected bias early.
What role does data governance play in machine learning projects?
Data governance ensures that the right data are available, reliable and compliant. Without a clear governance structure you risk data leaks or unreliable insights, which become apparent during audits or ISO certification.
Is machine learning applicable for small and medium-sized businesses?
Absolutely. Thanks to cloud services and off-the-shelf models, entry costs are falling. Platforms like Mind integrate multiple AI providers and allow sophisticated analyses without deep data-science expertise. :)
How quickly does a model become outdated?
That varies by domain. With rapidly changing data—such as financial transactions—drift can appear after weeks. In more stable settings, for example industrial sensor data, a model can remain useful for months or years. Monitoring and periodic retraining are therefore standard practice.